Выступление HAMANO Tsukasa (Open Source Solution Technology Corporation) на конференции LDAPCon 2017, Брюссель, октябрь 2017 года. Оригинал статьи (PDF) и слайды к этому выступлению (на английском языке).
Часто возникают задачи, когда требуется использовать различные источники данных (облачные базы данных или NoSQL) в качестве хранилища данных о пользователях так, чтобы общение с их внешним интерфейсом происходило по протоколу LDAP. В OpenLDAP предусмотрена довольно гибкая возможность разработки дополнительных модулей механизмов манипуляции данными по Вашему желанию, но это требует больших трудозатрат на разработку и временных ресурсов. Для ускорения разработки подобных механизмов в OpenLDAP уже есть модуль back-perl, но разработка на его основе всё ещё малопрактична, поскольку в этом модуле используется только один интерпретатор, а OpenLDAP — многопоточное приложение. В этом документе представлен новый механизм манипуляции данными OpenLDAP back-mruby, позволяющий практически любому легко и просто разрабатывать свои механизмы доступа к данным. Также здесь объясняются причины, почему мы предпочли использовать именно Ruby, а не Perl или Python.
Существует множество реализаций языка Ruby. Наиболее популярна реализация, которая является официальной, — CRuby. MRuby — это новая реализация, совместимая со спецификацией Ruby 1.9. MRuby имеет небольшой размер по сравнению с обычными реализациями Ruby и отлично работает на небольших устройствах. Также предполагается, что MRuby лучше подходит для встраивания в приложения, чем для выполнения в качестве отдельного приложения.
Matz, создатель CRuby, начал проект MRuby в 2010 году. Этот проект поддерживается METI (Министерство экономики, торговли и промышленности правительства Японии). В настоящий момент MRuby разрабатывается на github.com и распространяется под лицензией MIT.
В OpenLDAP уже существует механизм манипуляции данными Perl (back-perl). Он позволяет разрабатывать гибкие механизмы доступа к данным для OpenLDAP путём реализации обработчиков запросов LDAP на языке Perl. back-perl больше подходит для интеграции с высокоуровневыми хранилищами данных, нежели с низкоуровневыми базами данных, такими как BDB и LMDB. Он может использоваться для добавления интерфейса протокола LDAP к различным моделям хранилищ данных, таким как реляционные СУБД, NoSQL или облачные сервисы хранения данных.
Однако, у back-perl имеется ограничение, заключающееся в том, что у процесса slapd есть только один интерпретатор Perl. Теоретически в рамках одного процесса может быть создано несколько интерпретаторов Perl, но API для работы с интерпретатором не является потокобезопасным, поэтому такие интерпретаторы не могут выполняться параллельно. Следовательно, применение back-perl не является практичным, поскольку в нём в единицу времени выполняется только один обработчик Perl, хотя процесс slapd является многопоточным.
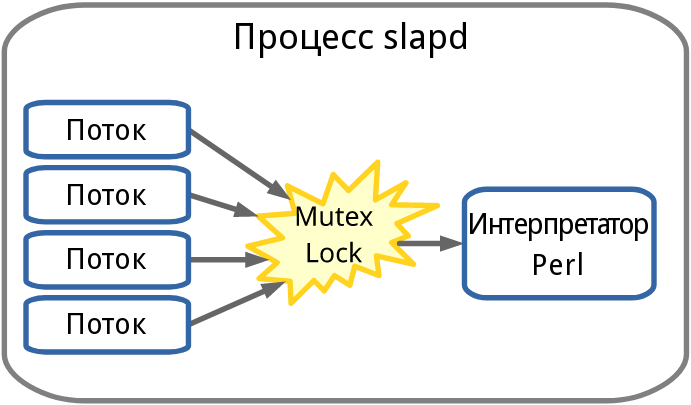
Рисунок 1: Модель процесса back-perl
Сначала мы пытались заменить интерпретатор Perl механизма back-perl на Python или CRuby, но у них имеется такая же проблема. Python позволяет создавать несколько подинтерпретаторов в одном процессе, но им требуется получать GIL (глобальную блокировку интерпретатора), когда объекты python находятся в работе.
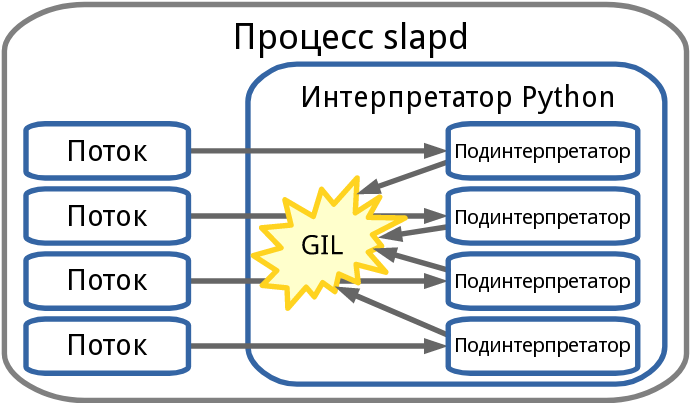
Рисунок 2: Модель процесса back-python
В итоге мы начали разработку механизма манипуляции данными MRuby для OpenLDAP. В рамках одного процесса мы можем создать столько виртуальных машин MRuby, сколько потребуется. MRuby решает проблему блокировок. Пространства памяти виртуальных машин полностью независимы и не влияют друг на друга. В механизме back-mruby каждому потоку slapd назначается собственная виртуальная машина MRuby. Таким образом, потоки OpenLDAP могут эффективно выполнять код Ruby в параллельном режиме.

Рисунок 3: Модель процесса back-mruby
Конфигурация механизма back-mruby очень проста. Требуется только задать параметр rubyfile в конфигурационном файле slapd.conf как показано ниже. slapd загрузит файл с Ruby-скриптом, в котором определены обработчики запросов LDAP.
В файле slapd.conf указывается:
rubyfile example.rb
Рассмотрим примеры определения обработчиков запросов LDAP в Ruby-скрипте. В первом из них показана реализация обработчика запроса BIND, в котором успешная аутентификация происходит с вероятностью 1/2.
def bind(op)if rand(2) == 0LDAP_SUCCESSelseLDAP_INVALID_CREDENTIALSendend
В следующем примере показана реализация обработчика запроса BIND со статическими записями пользователей. Данные LDAP-запроса передаются в качестве аргумента op, в который просто отображается структура op процесса slapd. К примеру, нормализованное DN будет доступно как op['ndn'].
def bind(op)# User DN and password mappingsusers = {'uid=alice,dc=example,dc=com' => 'secret1','uid=bob,dc=example,dc=com' => 'secret2',}ndn = op['ndn']cred = users[ndn]if cred == op['req']['cred']LDAP_SUCCESSelseLDAP_INVALID_CREDENTIALSendend
Функция обработчика запроса Search должна возвращать список записей в формате LDIF или код ответа. В следующем примере показано, как реализуется обработчик запроса SEARCH, обслуживающий запросы с диапазонами base и one.
def search(op)scope = op["req"]["scope"]if scope == LDAP_SCOPE_BASEsearch_base(op)elsif scope == LDAP_SCOPE_ONEsearch_one(op)elseLDAP_NO_SUCH_OBJECTendend# Returns base entry.def search_base(op)ldif = <<END_OF_LDIFdn: dc=example,dc=comobjectClass: topobjectClass: dcObjectobjectClass: organizationdc: exampleo: exampleEND_OF_LDIF[ ldif ]end# Returns two user entries.def search_one(op)entries = []ldif = <<END_OF_LDIFdn: uid=%s,dc=example,dc=comobjectClass: topobjectClass: accountuid: %sEND_OF_LDIFentries << ldif % (["alice"] * 2)entries << ldif % (["bob"] * 2)entriesend